How to By-pass the Renderer Process in Electron
One of the most noticeable factors contributing to a poor user experience for developers is slow performance and instability. Every now and then we dedicate a meaningful amount of time to making things run smoothly and fast for everyone.
Our latest significant effort was to improve loading performance of large knowledge bases in electron application. By by-passing the renderer process while loading the data, we have managed to ship a 100x faster markdown loader. Doing so, we have removed any constraint on the amount of files loaded, and enhanced the in-app experience during the import.
This article is a long technical explanation of what we did. If you are interested in short summary of our findings, here is the TL;DR:
Passing messages through the renderer process will block it, making the app unresponsive. You ideally want a direct message channel between the web worker processing the data and the main process providing the data. To enable communication between web workers and the main electron process, you need to bypass the context isolation and create a separate channel. This will enable direct communication between the renderer process and the main process. This allows you to send Message Channel ports between web workers and the main process.
Markdown to HTML Parsing
A recent update has focused on markdown parsing and interoperability with other markdown editors. The performance of our app started to take a hit while load testing the new parser on thousands of markdown files.
Writing experience started to decline at around 300 files and the app slowed down noticeably at 500. We were not happy with this. Some devs might work with more data than that.
Why Parse Markdown to HTML?
The editor we use - TipTap, is not markdown native. In order for us to store your data as markdown files, while also showing them in TipTap, they need to be parsed from markdown to prosemirror json, or html. In acreom, we use HTML for 2 simple reasons:
We use it to show previews of pages.
We use it to display the rendered pages when sharing them.
All the work acreom does with your content is done using html - storing in memory and IndexedDB, displaying in editor, editing the html inline, etc. When the files are ready to be written back to the file system, they get parsed to markdown again.
acreom could use prosemirror json to do the postprocessing and tracking changes, but at this moment it would be the only use case for the prosemirror json, which does not validate storing another format for the data. It would simply use more memory for a small benefit when doing some operations.
Most of the time our users work on a single file. In this case the parser takes only a few milliseconds (< 4ms, 95th percentile). The problem shows itself when you start loading a new vault, or import thousands of markdown files. Parsing needs to be done over and over again for every file you load.
Main vs Renderer Processes in Electron
This blog is not meant for explaining how electron processes work, but in short: Electron has two central processes: the renderer process and the main process. The renderer process renders the web content. The main process is the application's entry point and has access to the file system. You can learn more about the processes here.
Loading the Markdown Files
If you want a snappy electron app, the renderer process should be used solely for its intended purpose - rendering. Long running operations in the renderer process result in a laggy app and non-interactive UI.
When you load files from the filesystem, sending them through the renderer process means tons of serializing and deserializing from and to v8 serializable. This was exactly the case in our old setup - the loaded files were passing through the renderer process, which led to blocking the interactions with the app.
Serializing Data Between Processes

While serializing a small amount of data is not noticeable when rendering content at 60fps, trying to send megabytes of data makes for a different story. Our old way of reading and parsing of markdown files worked like this (see image):
Database worker requests listing of files in the vault.
Request passes through the renderer process and is received by the main process.
Main process invokes listing of all files and serializes the result and sends it to the renderer process.
Renderer process deserializes and serializes the result and passes it to the Database worker.
Database worker iterates over the file paths in batches and asks the main process to read the files from the file system.
Request passes through the renderer process and is received by the main process.
Main process loads the files requested, serializes them and sends them to the renderer process.
Renderer process deserializes, parses, and serializes the content and sends it to the database worker for storing.
The red circles in the image represent a blocking operation on the renderer process. As you can see, this process is not ideal, because the renderer process acts only as a middle man and its sole purpose is sending data from one process to the other.
While doing so, both the renderer and the main processes are blocked, because serializing data is a blocking operation. Since the renderer process does not need the data at any point during the loading, cutting it from the process is an obvious improvement that should enable a smooth experience while loading large vaults.
Optimizing Loading Time
Now we have clearly defined our problem: Passing messages through the renderer will block the process, making the app unresponsive.
Finding the solution was a bit tricky, because the resources we could find were limited. An approach we wanted to try was to see whether a web worker (such as the database worker) could be connected to the main (electron) process. Doing so would allow us to pass the data directly from main to a webworker, without blocking the renderer process.
This would not work as the electron's context isolation prevents you from sending the DOM MessageChannel port through IpcRenderer. We came up with creating a channel between the main process and web worker based on this issue.
Connecting the Main Process and Web Worker
Electron has a port functionality (similar to message port) - allowing messages to be sent from one port to another. The port can be used to communicate between the renderer process and the main process using electron message channel, but it can not be used to communicate between the main process and a webworker, as those use different communication channels. A channel that both a web worker and the main process can use can only be created in preload.
A Better Way to Parse Markdown
When the app starts, a message channel gets created in preload. One of the ports gets sent to the renderer process, while the second gets sent to the main process.
Later, when importing data, the database worker creates a message channel, keeps one port, sends the other port to the renderer process, which sends it to the main process through the channel created at startup.

Now the actual import process looks like this:
Database worker receives import trigger with a file path to import.
Database worker invokes a list directory recursively in the main process.
Main process returns all files in the directory, with links to parents.
Database worker then invokes the loading action and creates a message channel between the main process and the database worker.
Main process loads contents of files in batches and sends them to the database worker through the channel.
Each batch is then parsed to markdown in utils worker and saved to the database.
When the import ends, the database worker closes the message channel created at the start of the load.
Optimizing the Optimized Parsing
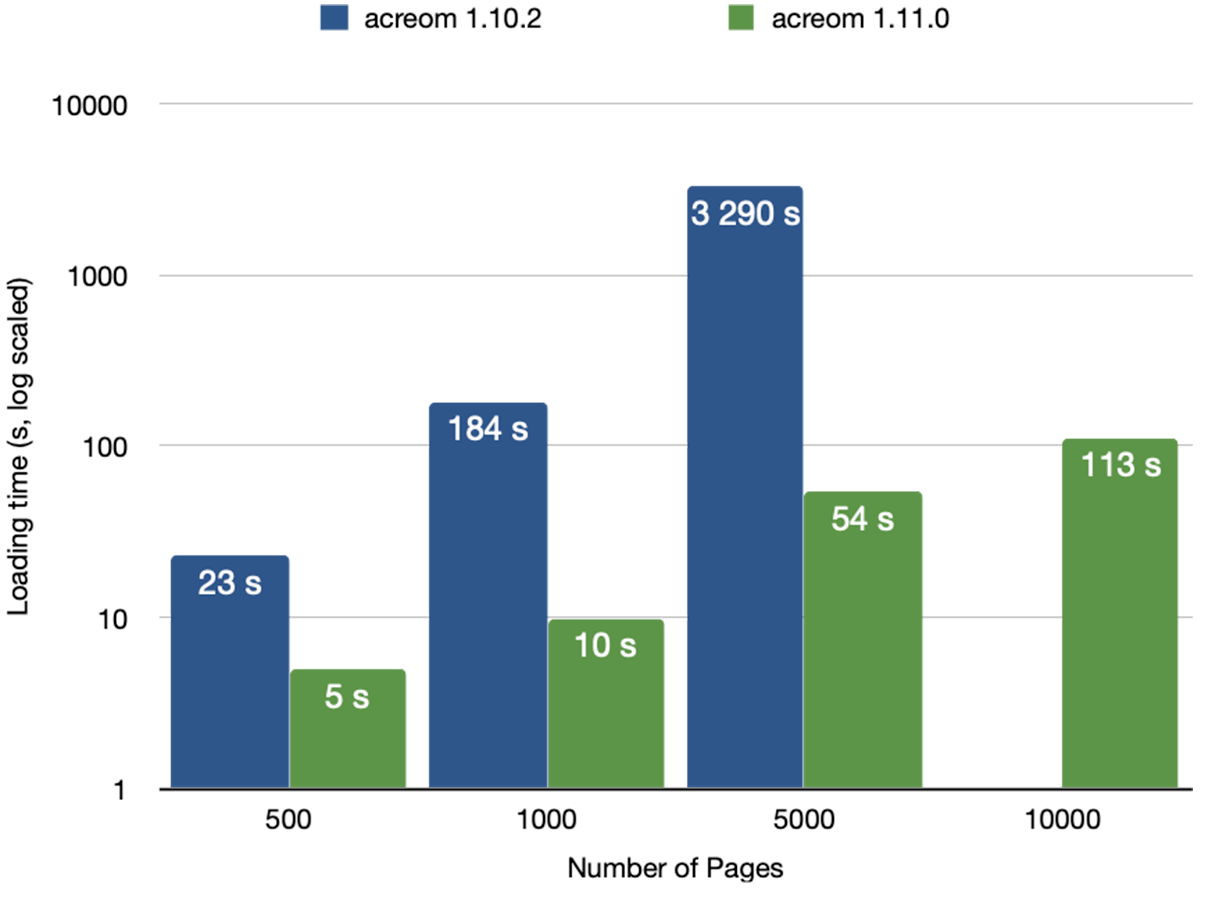
This alongside the caching of entities on the parser side was a huge improvement (the load is ~100x, if you import ~10k files) over our old solution. The comparison is shown in the following figure. Note the y axis is log scaled for readability. The loading is now faster and you can capture, search and browse files in acreom throughout the whole operation.
There is one improvement we know about, but decided it was an overkill and not worth our time right now. We could spawn a node worker, pass the port to the worker, therefore node worker (managed by the main process) would communicate with a webworker (managed by the renderer process). Not even the main process would be blocked in that case.
Right now we are offloading it only from the renderer process since modern laptops should get through the loading with ease (older might have a problem, but we could use different batch sizes, or try other tweaks if the problem comes up).
Results
To evaluate the method, we have used the interconnected markdown dataset - https://github.com/rcvd/interconnected-markdown/tree/main created by Alexander Rink. We have loaded the data using the old acreom (version 1.10.2), the new acreom (version 1.11.0), and obsidian (version 1.4.14).
Below is a table showing the time it took to load (and in case of acreom also parse) all the files. We did not load the 10k dataset with the old acreom, because it would take a long time (7000 seconds as predicted by linear regression). Here is a link to a youtube playlist containing the recordings of our testing: playlist
Loading times (s) | acreom 1.10.2 | acreom 1.11.0 | obsidian 1.4.14 |
500 pages | 23s | 5s | 2s |
1000 pages | 184s | 10s | 3s |
5000 pages | 3290s | 54s | 8s |
10000 pages | 7000 (predicted) | 113s | 15s |
Obsidian side-note: why is it so fast? Our assumption is that Obsidian, unlike us, works with markdown files directly, since you are editing raw markdown anyway, so contrary to acreom, there is no need to parse the files it loads. That is why the only operation it does is indexing.
All of the improvements are already released in v1.11.0, you can already try it out after downloading acreom - acreom.com/downloads. Tweet us what you think @acreom!