Shipping Large ML Models with Electron
How do I ship a large machine learning model with an electron app? Not so long ago, I couldn't find a resource to solving this problem, so I decided to do a write up of my experience, which could be useful for others. Let's dive right in.
Since the beginning of our work on acreom, we wanted it to have an IDE-like experience with real-time autocomplete suggestions in the context of knowledge base and tasks.
The first problem we decided to experiment with was to classify free text as a task or event. It turns out that building a binary classifier for such a use case is relatively easy; however, shipping it with Electron is the tricky part.
But why ship it with electron in the first place? It mainly boils down to speed of inference and user privacy. Hence, the problem presents the following specs:
fast inference (required for real-time suggestions)
minimum memory footprint
a good user experience means high accuracy with low false positive rate
user privacy - no API calls, fully offline, shipped on the client.
The ML Part: Exploration & Fine-tuning
In spite of having no prior datasets available, this was a relatively fast and easy task. I have manually created a small dataset of roughly 1200 samples, where a task / event class looks like this: code tomorrow morning and negative class like code is simple, with a roughly 50/50 class balance.
An interesting side observation was to learn the semantics of such examples where 2 opposite samples share the same words but not the meaning. Later on, this allowed me to take a few actions to increase the overall performance of the model. I left out the lemmatization in the preprocessing pipeline and created feature engineering that applies additional weights to queries which start with verbs or include time for example. I have used quickadd, an open-source library for parsing time & date I have forked from ctparse (and upgraded with a lots of modifications)
After many experiments with different techniques and models, I settled with a bi-directional LSTM written in Pytorch. This worked surprisingly well considering the tiny dataset it was trained on. After some additional fine-tuning, I was happy to end up with F1 scores around 0.95, which is in the production territory for this use case. Great, the model works. Now all I need is to figure out the electron stuff.
Figuring out the Electron Stuff
This is where things get hairy. Firstly, The trained LSTM model with it's custom word embeddings was not small in size by any means. It's dependencies, with custom word embedding and ~70k parameter model, had over 4GB in size all together!
Secondly, I wanted to keep our ML development process lean and fast when it comes to shipping in production. A few fundamental building blocks were necessary, so I could build future models systematically.
Okay, so maybe I can have some sort of an API interface written in python that would somehow communicate with the electron and it would all be frozen as a separate executable with the model, shipped alongside electron? Maybe this could work.
Inspired by the IDE language server protocol, I created an API interface between the electron and the Python ML interface. ZeroMQ turned out be an invaluable resource as a fast and lightweight messaging queue between the two.
Now all I needed was to freeze the Python interface into an executable that would accept requests from the electron, infer from model, and send response back.
Using PyInstaller
PyInstaller seemed like the most maintained and developed tool to freeze python script into an executable, so I went with it. As expected, the freezed interface with the model was gigabytes large, so I had to figure out how to squeeze this. Fortunately, Onnx worked wonders and packaged the model into an inference only state, so I could throw away the Pytorch and Torchtext dependencies when freezing with Pyinstaller. Now the size of the executable with the model was 43MB instead of 4GB.
Pyinstaller throws a curveball every now and then with missing .dylib files in the process, but nothing that can't be figured out with symbolic links to the local dependencies. What did the trick was to offload heavy Pytorch and Torchtext libraries with their dependencies to the bare minimum so the script could work.
Inner Workings
Here's brief rundown of how all of this works:
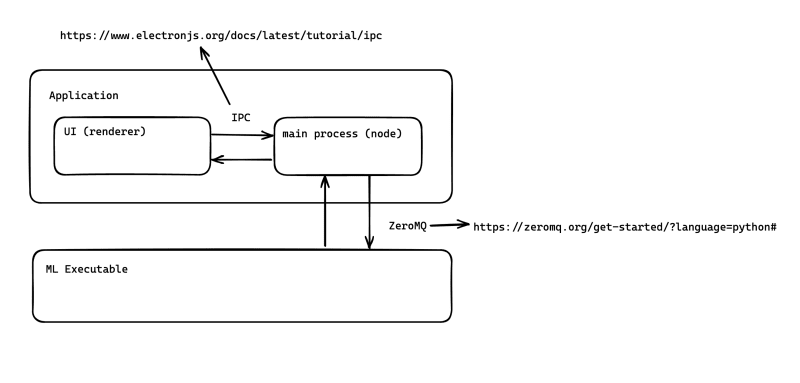
When the electron is opened for the first time, the main process retrieves available port and runs the ML executable, listening to the port. I have built in a retry logic for error handling and for disconnecting handlers on close.
The electron then sends an
initializemessage through the ZeroMQ to initialize the ML model, so it listens for requests. This came as an additional logic to prevent sending requests to the executable which was not yet initialized in the step #1. After the initialization, it listens for queries as JSON objects. Here's a sample query:
{
"requestId": {
ID
},
"action":"infer",
"service":"classifier",
"data": {
"data":"code tmrw 7-9pm"
}
}When initialized, the executable listens for messages with the
servicetype, reads it's request, and runs it through the appropriate model for the inference.Since this model is a binary classifier, the response propagated back through the messaging queue to the fronted of the application, like this:
{
"data": "1",
"requestId": {
ID
},
"service": "classifier"
} The Frontend takes care of triggering the visuals and converting the text into a task component upon the confirmation from the user within a timeout of the listener. The end result looks pretty solid!

This experiment went to production soon after, and while it's not the best and most desired UX implementation, it served with good learnings for future work.