The Quest for a Great Search
Large knowledge bases often face the difficult challenge - accessing relevant information fast. We failed to solve this with our first search implementation, but we gave it another go and learned some useful insights along the way.
The Do it All Search Mistake
acreom has had search since its beginnings - serving both to navigate pages, but also as a full-text search. The search was trying to achieve too many things without properly communicating what’s really happening. The experience of searching was seemingly simple - you open a modal, type your query and see the results with a preview on the side. It may sound as if everything was working, but there were issues.
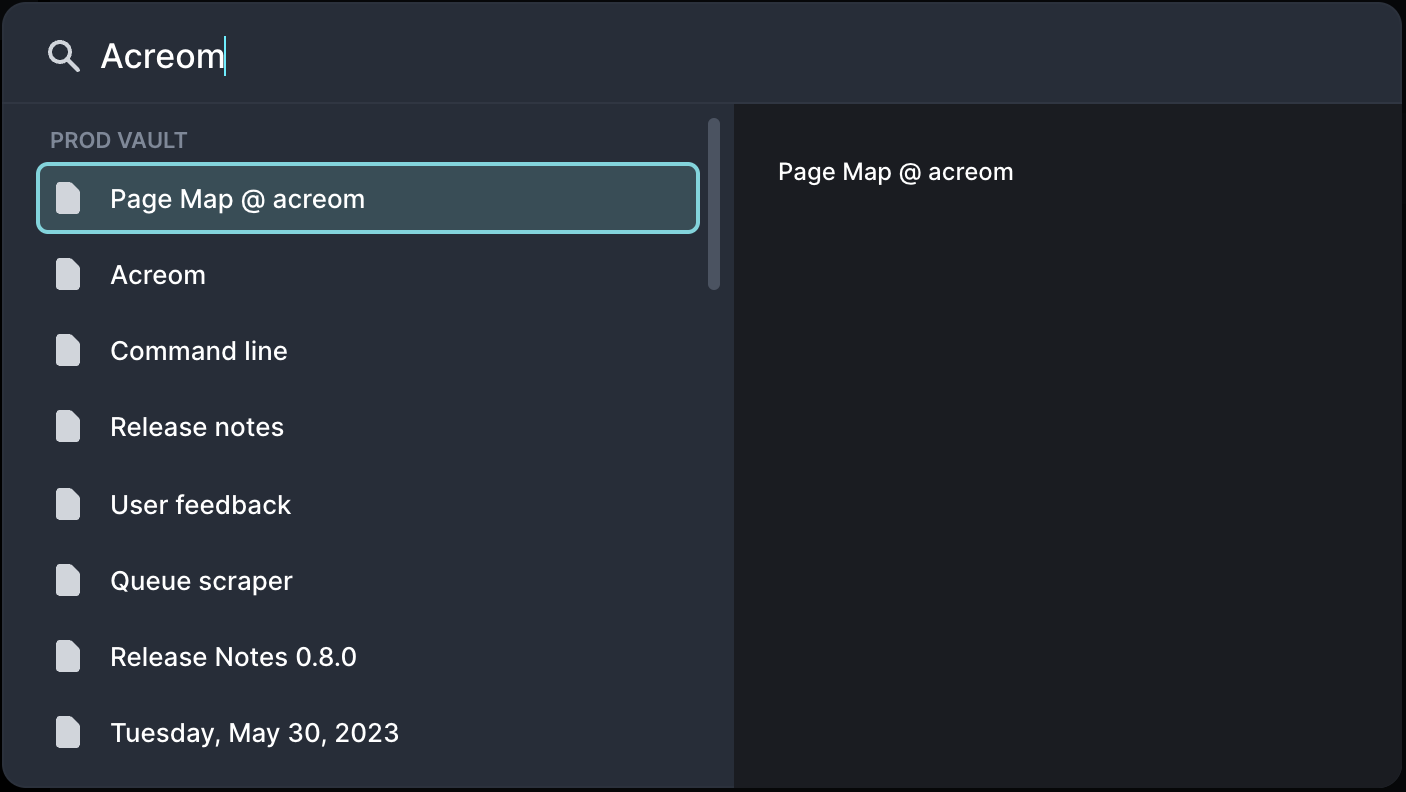
Just a quick glance at the image above can tell you the experience was pretty bad.
acreom did not let you know exactly what your query matched. There was no highlight on search results - not even in the preview, leaving you to wonder, what the best match is and why?
The ranking of search results was poor, often resulting in the wrong order, causing even more confusion.
We wanted the search to also function as a navigation component and we even added our NLP date parsing to enable searching queries like
today,tomorrow, orin 2 weeks. This enabled you to go to the exact My Day or find pages you recently worked on. But when you did search using nlp, you got a hot mess of results where the date query matched the content, title and even formatted tasks or events inside the page alongside the page metadata.
To get it right this time, we have defined the optimal search experience for a knowledge base.
Focus is Key
Searching starts with a goal: I want to access a specific piece of information. One of three scenarios will follow:
I Know What I Want and I Know Where to Find It
This is the easy case. You use simple navigation and you access the exact file.
While working in an IDE, if you know where you want to navigate, you use the "go to" search, type the name of the file and you are there. It’s as quick as that.
I Know What I Want, but I’m Not Sure Where to Find It
This one is a bit more tricky. You know the context of what you’re looking for, but you don’t know where exactly it is - so you search the contents of your knowledge base.
In an IDE, when you are looking for something more specific, like the usage of a function, you open the content search, type the function name and then explore the content of your results.
I Have a Slight Idea of What I Want, but I don't Know Where to Find It
This is the most difficult case to get right, because along with the searching, you are also dealing with exploring your knowledge base. Using a basic full text search won’t be enough, as common matches work only if you know what you’re looking for.
The search alone is often not enough, so you regularly see some other way of solving this. Tools like Obsidian or Logseq tried to deal with it using backlinks and graph view.
In graph view, you can view and navigate between linked entities in a 2D plane. While helping you navigate when search falls short, it requires a certain amount of foresight when creating your pages and makes you think for your future self. You need to constantly link your current knowledge to the relevant content from the past, which is tedious and time consuming.
A great search should solve all of these scenarios with ease. It should enable you to retrieve information almost instantly when you know exactly what you want. And when you don’t, it should lead you in the right direction and help you explore your existing knowledge base.
acreom Search
Clearly defining the various routes one can take helped us realize where we have failed the first time. We've wanted to keep both the title-based search, used mainly for navigation, and contextual search, used for retrieving information, working simultaneously, which has led to poor results. As a solution, we've decided to split the two scenarios and create a clear path for each one.
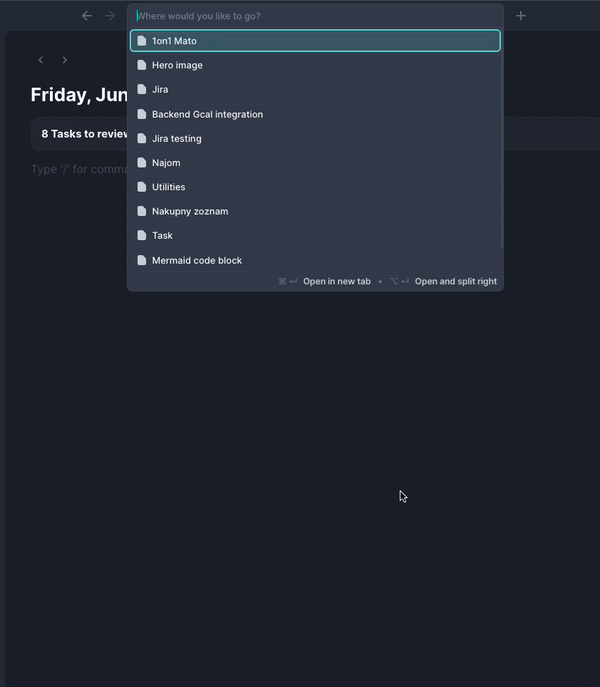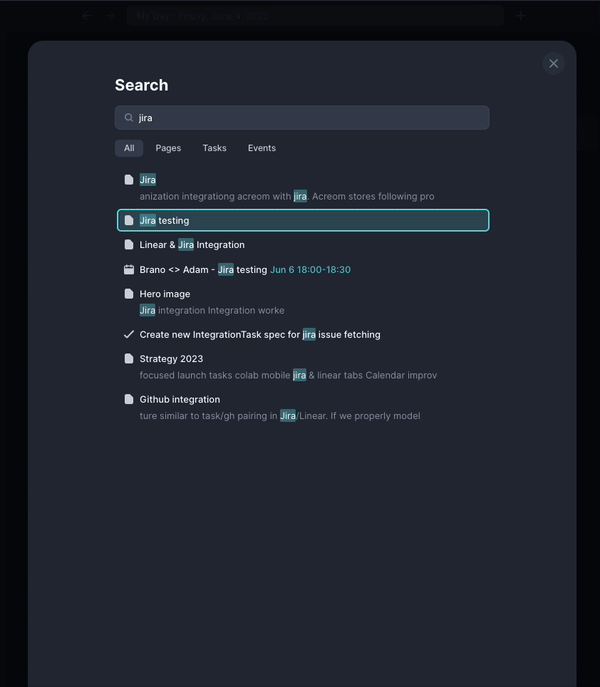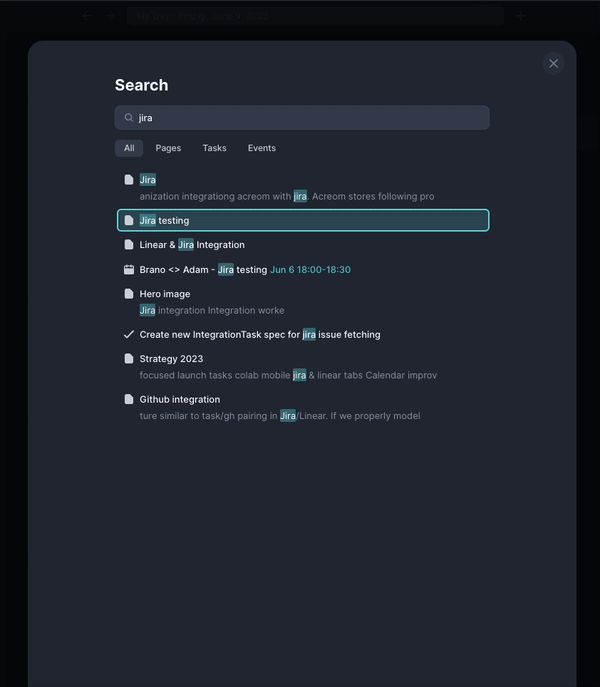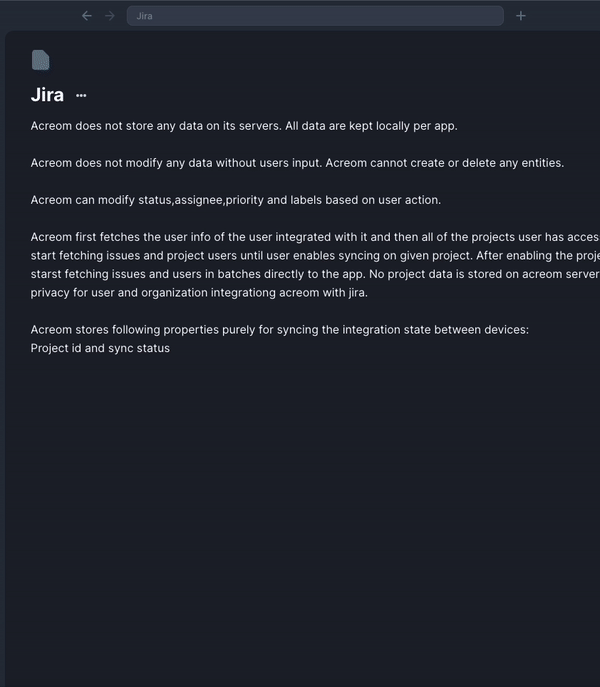
First part of the solution was to create a navigation search. It allows searching all entities present in acreom using title and date. It can be used to navigate anywhere in the app, including all data from existing integrations.

You can quickly jump around the app and navigate anywhere within milliseconds, using only your keyboard. The navigation sits on top of the UI and is quickly accessible using a keyboard shortcut. We've also added some basic commands, allowing you to quickly create pages.
To deal with the second scenario, we have created an extended search view which can be accessed either from navigation search or by using another keyboard shortcut. The extended view gives you an option to search the content of entities alongside their title and metadata, such as hashtags and dates.
For the third part of the problem, we have created the Query functionality using acreom Assistant integration. You can use ChatGPT integrated with acreom to query your knowledge base, allowing you to ask questions using natural language, and get answers extracted from your pages, along the source pages which were used to generate the answer.
Technical Rundown
The whole search runs directly in acreom, so we could not use out of the box solutions like algolia, or robust solutions like elasticsearch to do the heavy lifting. Furthermore, data leaving acreom would not conform to our privacy first and data ownership policies. These reasons led us to use a js full text search library.
Choosing the Library
We iterated over a few different options:
flexsearch had the lowest memory consumption and fastest query time, but was lacking in a few core aspects - it did not provide the result score, match positions, or any indication of what it matched except for the field. It also did not provide any option for dynamic boosting. Building a custom solution to all of this was just not worth it.
Fuse.js provided all that flexsearch lacked, but it was way too slow and memory hungry. We needed a solution that would be able to index thousands of entities on multiple fields, all while providing query results in milliseconds.
minisearch, which we have decided to go forward with. The difference in memory usage was just a few megabytes compared to flexsearch, it provides an explanation of what it has matched in the result alongside the score, and the query time was also up to par with flexsearch. The only thing missing was highlight intervals for fuzzy matches, so we made our own.
Match Highlighting
To display the highlights, we first parse the query to tokens the same way minisearch does, we then find the position of match based on the provided matched keyword in the result, pair the query tokens to the matched keywords based on their similarity, and then we compute highlight intervals in the text using index of the keyword, its length, and the most similar token in the query.
Since minisearch always returns the whole keyword, even when only part of the word is matched, we did not want to just highlight the whole match. Our solution enables partial and prefix matching of query terms in matched keywords, resulting in a better explanation of what the search matched.
Data Flow
We then designed a data flow that automatically indexed all entities and changes made to them across all vaults. acreom database generates change objects when you create, update or delete entities. Parts of the application listen for these changes and may act on them.
Keeping the search always up to date is simple, as we only need to listen to the changes made and update the index accordingly. No matter where the update comes from - whether locally, from sync, or user input, search index is updated instantly. We have decided to move the search to a separate web worker, which has enabled batch indexing without freezing the whole application or slowing down the database worker. This setup is easily extensible for all entities stored in indexedDB, which enabled us to make all data stored in acreom searchable.
Query Tricks
acreom is shipped with its own in-house made nlp parser called quickadd, which can extract date and time from any text. Your query is parsed by quickadd every time you type and if there’s any date present, the query is enhanced with the parsed date and entities matching the date are bosted.
This enables searching for daily documents, and pages based on their update timestamp. Simply typing yesterday into search will bring up all documents you worked on, meetings you had, and tasks you scheduled for yesterday.
You can label all entities in acreom and the new search supports label matching, allowing you to filter results based on the labels entered. We have decided to parse labels directly from the query as it could also be handled by quickadd. When you type a label into the search, all labels are prefix matched on results up until you put space after it. From that point on, exact label matching is done. All labels in a query need to match for a result to be shown.
This blog is part of acreom dev week. Check out our twitter, or join our Discord community to stay in the loop. If topics like this one excite you, check out acreom.com/blog for further reading.